How many new streams can be created per second in EventStoreDB?
To find out, let's write 10 million events across 10 million new streams and measure the rate at which they are written:
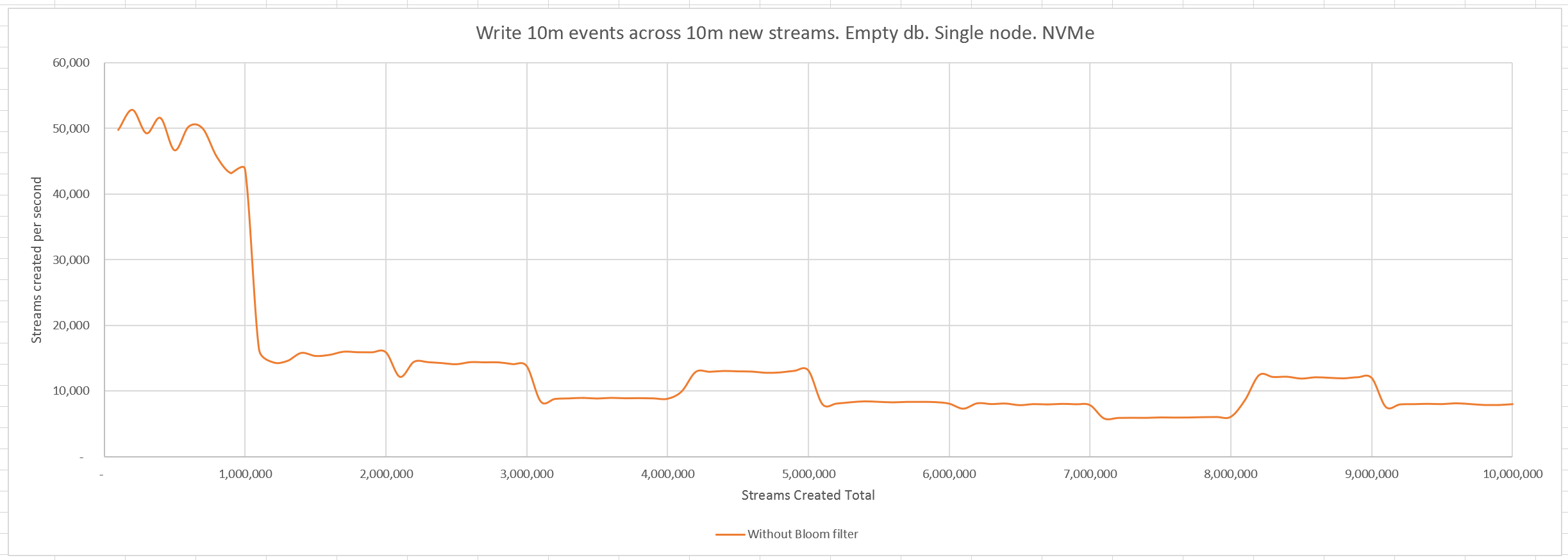
Curiously, at the 1m streams mark, the rate drops from ~45k/s to ~15k/s.
Whenever an event is written to EventStoreDB, it is labelled with the event number that it occupies in its stream. This facilitates optimistic concurrency checks so that an application can read a stream, generate an event, and then write that event to the stream on the condition that the stream has not been appended to in the meantime. Therefore, when writing an event, EventStoreDB needs to determine the number of the last event written to that stream. This information is held in caches, of course, but since in our experiment we are writing to a new stream every time, it is a guaranteed cache miss. At that point, EventStoreDB will check the indexes.
EventStoreDB accumulates 1m events at a time in an in-memory index before writing them to disk as a batch. The first time this happens the index check becomes significantly more expensive, and this causes the drop in throughput. The throughput can be seen to drop slightly more each time another index file is written (since there are more files to check), and increase when index files get merged together, reducing the number of files to check.
Performance improvements to the index are in progress at the moment, but what we really need here is a quick way to determine that a stream does not exist - then we can bypass the index check altogether.
Solution: a Bloom filter
A Bloom filter can quickly decide between an element being possibly a member of a set or definitely not a member of a set. It is an array of bits that all start off set to 0. When an element is added, the element is hashed (usually multiple times) and a bit in the array set to 1 for each of the hashes. To check if an element is present, it is hashed in the same way and the bits checked. If they are all set to 1 then the element is possibly in the set (they might be coincidentally set to 1 by other elements), but if any of the bits are set to 0 then the element is definitely not in the set. As more elements are added to the set, more bits are set, and the effectiveness of the filter will be reduced. Therefore, the filter has to be large enough in order to continue being effective.
The Event Store engineering team have implemented a Bloom filter. Let's configure it to be 15mb big and check it when looking up the latest event number in a stream. If the Bloom filter responds that the stream does not exist, then we do not look for it in the index.
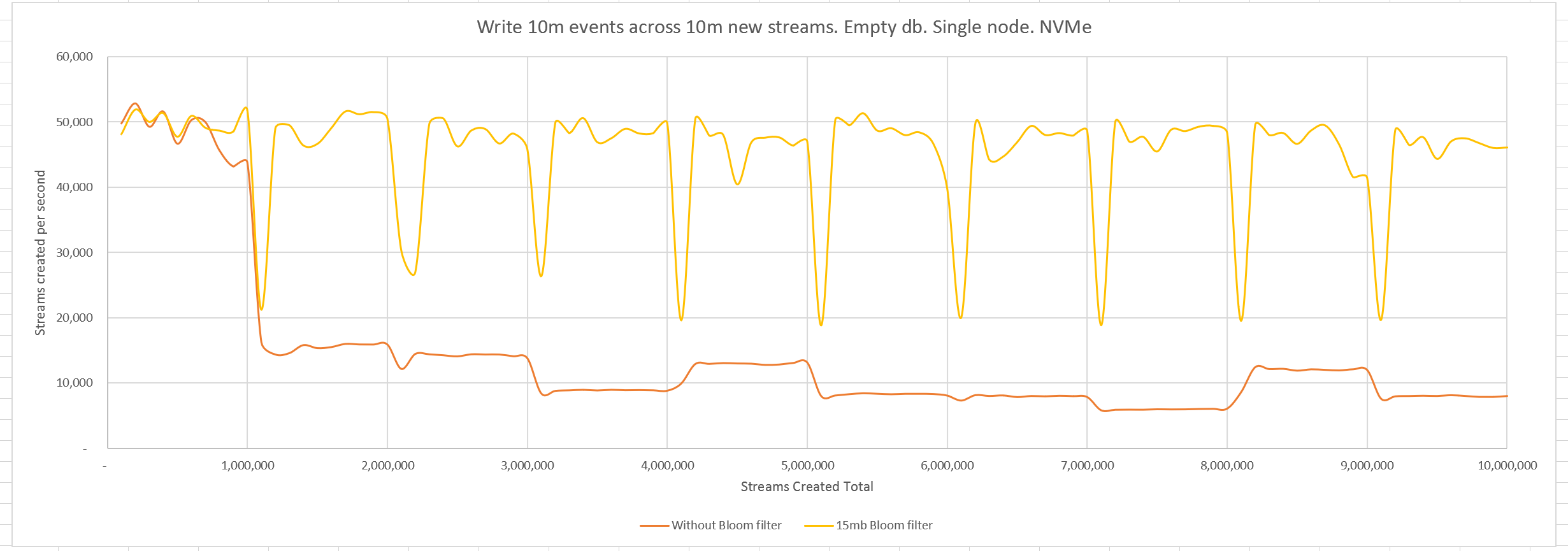
Now we see the throughput is maintained at ~50k/s across the run. The dips in throughput are caused by the previously mentioned flushing to disk of each batch of 1m events that the index has accumulated. This was present in the first graph, too, but since the rate was lower it was not so noticeable.
Saturation
We know that the Bloom filter will become less effective as it fills up. Let's try one more run, this time with a 1mb Bloom filter, to see how the performance will be affected.
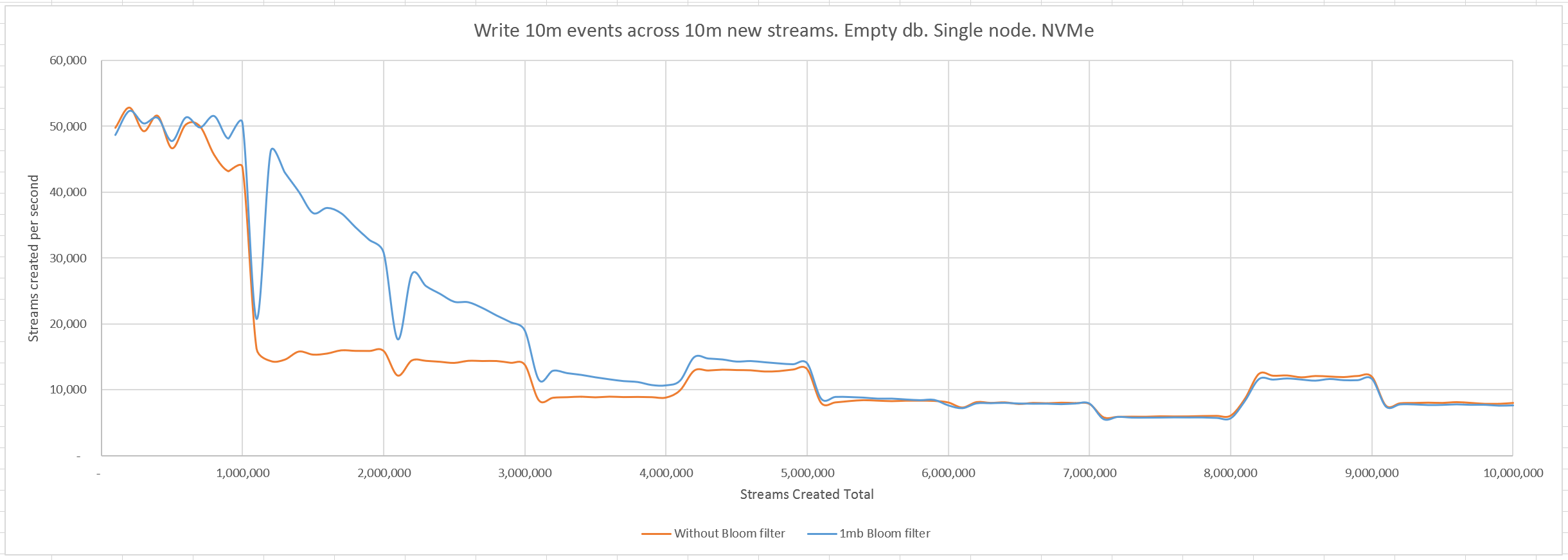
We see that the throughput gracefully degrades as the Bloom filter fills up, until it is the same as if we did not have a Bloom filter at all, but does not drop below that point.
Configuration
The Bloom filter will be available in a future version of EventStoreDB and configurable with the --stream-existence-filter-size configuration option which is specified in bytes. We recommend setting it to 1-2x the number of streams expected in the database. This many bytes will be stored on disk for the filter, and (up to) the same again in memory as EventStoreDB will use it as a memory mapped file.
The setting can be changed, and this will result in the Bloom filter being rebuilt. A setting of 0 disables the filter. The default is 256mb.
Notes on implementation in EventStoreDB
EventStoreDB accesses the Bloom filter as a memory mapped file. It maps the entire file on start so access to the filter for reading and writing is quick. The operating system will flush pages of the file to disk as it pleases and occasionally EventStoreDB will force a flush of all the dirty pages, followed by writing a separate checkpoint file. Reads and writes are not blocked during this process. On start, the filter is caught up to the current log records using the checkpoint as a starting point.
Data integrity is ensured by using the last 4 bytes of each cache line to contain a hash of the preceding 60 bytes. In this way, if a power cut were to happen resulting in bad data being written to disk, it is detected on start. When corruption is detected, the bits in the offending cache line are all set to 1, ensuring the filter continues to function correctly, at the expense of some efficacy. If (somehow) the file becomes more than 5% corrupted then it is rebuilt.